
The role of the Operating System in the era of modern AI – Part 1
TLDR; With the advent of ubiquitous personal computers and the internet in the late 20th century, there were many fears about computer security and existential risk, and there were many calls for new laws and regulations. Arguably, though, the most successful countermeasures against computer misuse are built into our technology; we design security protocols to prevent or discourage attacks that are enforced automatically by the device’s operating system. AI Systems are, first and foremost, computer systems, and so we might expect AI safety to follow a similar trajectory. As large-language models continue to make inroads into our digital ecosystem, what effect will this have on the way that we secure our apps, and how we design the operating systems of the future?
The rise of the Natural-Language User Interface (NLI)
For a while we’ve had the ability to interact with digital assistants like Siri using natural language, but this has been more often than not a frustrating and error-prone exercise. However, recent advances in Large-language Models (LLMs) and transformer-based architectures for natural language processing have the potential to change this, allowing apps to better understand instructions in natural language. With Google Assistant getting an AI makeover, it is likely that Apple will follow suite.
The ease with which LLMs can now be deployed means that potentially all of our apps can now be equipped with a Natural-Language User Interface (NLI), including the Operating System (OS) itself. For example, “power users” are already familiar with using the command-line interface (CLI), aka. shell, to perform tasks like changing configuration settings and copying and moving files. But LLMs can easily translate natural-language into shell commands, so we instantly have a natural-language interface for managing our computer.
Moreover, we can use the same approach to equip any existing app with a natural-language interface. For example, we could easily equip a fitness app with an NLI so that we can ask it to provide a summary of our progress towards a training goal. In the short-term, we are likely to see a proliferation of NLIs for our existing apps.
However, the rise of NLIs is not the only way LLMs will impact on our apps; LLMs also give us the ability to endow our apps with more autonomy, and turn them into something more capable called an “agent.”
The Transition from Apps to Agents
Plugins together with lang-chain give the LLM both “read” and “write” access to the world; the LLM is not only able to fetch information about what is happening in the world, e.g. using a search-engine API, and track the important changes, but can also change what is happening in the world, e.g. by sending an email or making a financial transaction. That is, an augmented LLM can both observe the state of the world, and can also act in the world. An LLM app that is augmented in this way can be given instructions to perform a real-world task. Moreover this task need not have been anticipated in advance by the app’s creator.
Entities that are able act autonomously in the world like this are called agents (Wooldridge 1997), and there are many projects building general-purpose agents based on an LLM substrate. The ultimate vision is that these are general-purpose assistants, capable of, e.g., helping us work through our to-do list.
If we have general purpose LLM agents, will we need apps any more? I think the answer is yes, and one important reason has to do with the way we grant permissions and compartmentalise our data.
Consider the example of our fitness app. In addition to giving it an NLI, we could also start to delegate some fitness-related tasks to it. For instance, imagine setting a goal of running a marathon in six months. You might give your fitness app the task of planning your entire training regimen, from daily runs to strength training and diet. Using an augmented LLM, the fitness app can search the web for marathon training plans, adapt them to your specific constraints (like availability and current fitness level), send reminders or motivation emails, book sessions with trainers, and integrate rest days or cross-training based on your real-time progress or feedback. This app doesn’t just passively wait for input; it proactively helps you achieve a goal, i.e. it is an agent.
However, you wouldn’t want this fitness app to have unrestricted access to, say, your work calendar, personal finance apps, or private messages. Apps help compartmentalize our digital lives. We give explicit permissions to apps based on their functionality. Our fitness app, for instance, might get access to our health data and perhaps our calendars to schedule workouts, but not much else.
Now, bring an LLM agent into the picture. An LLM agent that is a general-purpose assistant could hypothetically manage a broad array of tasks, from managing emails and scheduling meetings to ordering groceries. However, a potential risk is that a general-purpose agent, if not appropriately restricted, could have too much access, possibly leading to unintended data sharing or even security breaches.
Thus, even in a world dominated by LLM agents, there’s a need for specialized apps.
For instance, a financial app would be a compartment that houses your transaction history, account balances, and investment details. The built-in permissions ensure that only certain trusted entities can access this data and, even then, with constraints. Perhaps a fitness app could pull a summary of your bank balance, but wouldn’t have the permission to initiate large financial transactions on your behalf. Similarly, a health-focused app would guard your medical history, fitness data, and other health metrics. While the fitness app might provide general health advice or schedule appointments, detailed health analytics would be sourced directly from the specialized health app.
The advantage of this compartmentalized approach is twofold:
- Specialization: Each app, acting as a data compartment, can focus on providing deep expertise in its specific domain. Whether it’s finance, health, entertainment, or any other area, the app can ensure the best, most tailored user experience by leveraging domain-specific prompts together with the the specific and detailed data it guards, in addition to domain-specific business-logic and data-access objects implemented in traditional software, which the LLM agent can invoke via an API.
- Security and Privacy: By limiting data access based on permissions, these compartments safeguard our personal information. This ensures that while we leverage the power and convenience of LLM agents, we’re not compromising on our digital security.
Ultimately, each of our apps will evolve into specialised agents comprised of an LLM back-end, various plugins and a set of specialised prompts with lang-chain code to glue everything together, with an overall architecture looking something like the following diagram.

Thus the traditional software components of an app that are developed in specialised programming languages such as Java, will gradually become encapsulated as specialised plugins of a more capable domain-specific LLM agent.
Natural language as the Universal Interface
As apps gradually morph into agents, we will have lots of agents interacting with each other; our phones and laptops will become hosts for Multi-Agent Systems (MAS). The field of MAS has a long history, predating the advent of GPUs, deep-learning and large-language models (Wooldridge 1997), as explained by one of the founders of the field in the video linked below.
In the early days of MAS research it was recognised that agents would need some way of communicating with each other, and specialised formal languages, e.g. the Agent Communications Language (ACL), were developed for this purpose (Labrou, Finin, and Peng 1999).
Now with the advent of LLMs, our agents can communicate in natural-language, not just with the user, but also with each other, which means that natural-language can become a universal interface, and we no longer require formal or specialised agent communication languages, as illustrated in the diagram below.
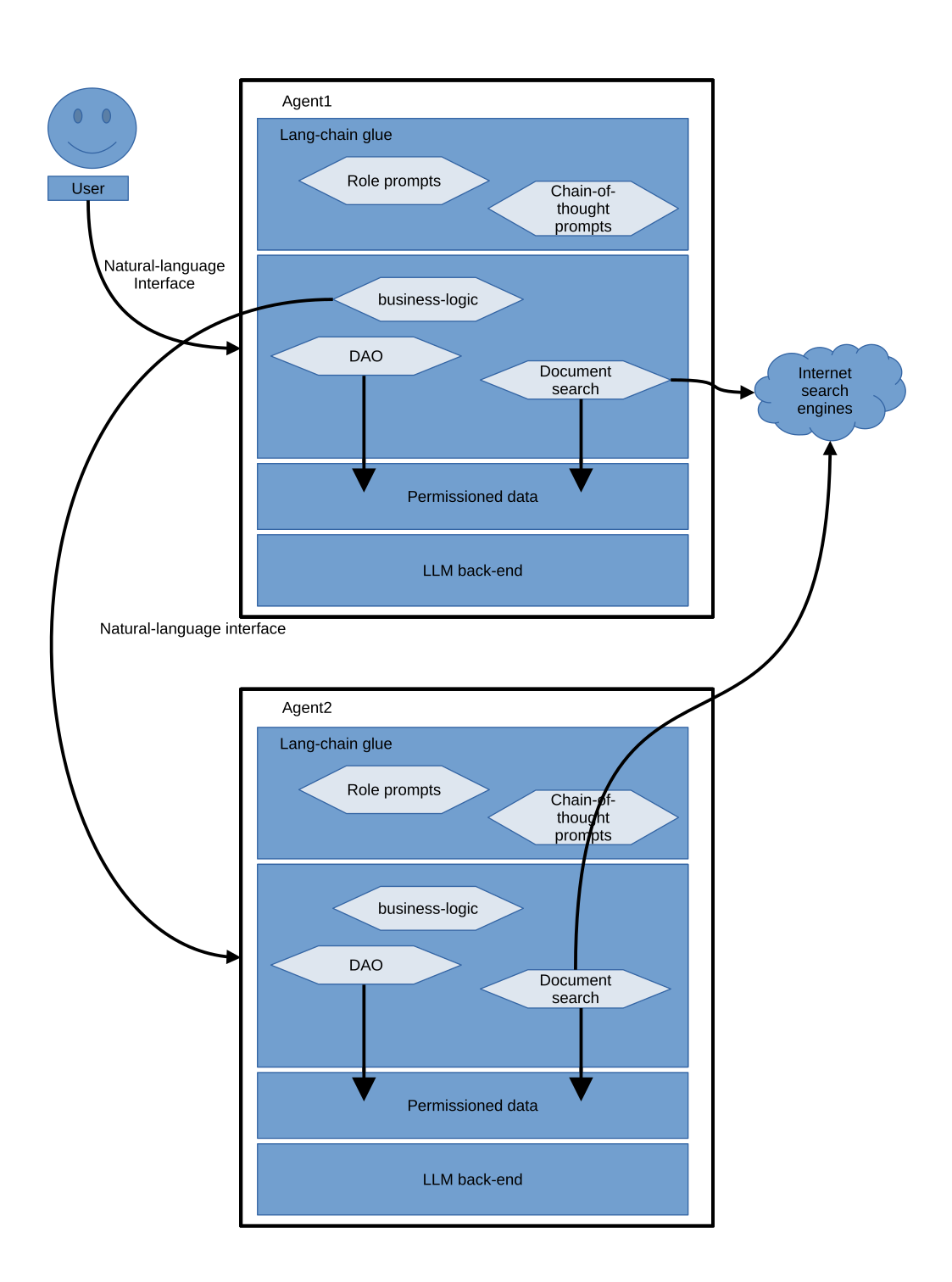
Agent/Application security
As natural-language interfaces become ubiquitous, and apps become more like agents, we will need a new approach to application security. AI safety has recently become very topical, with many doomsday scenarios being discussed. However, many of these existential risks are based on hypothetical scenarios with assumptions of varying plausibility.
In contrast to these doomsday scenarios, I think there are two non-existential, but immediate and tangible, risks that have already been demonstrated in the wild: principal-agent problems (Phelps and Ranson 2023) and prompt-injection attacks (Greshake et al. 2023).
Historically, much research in MAS has focused on economics, game-theory and incentive-engineering to ensure that a diverse ecosystem of self-interested agents are not able to disrupt the system for their own advantage (Phelps, McBurney, and Parsons 2010). Meanwhile it is increasingly understood that many traditional computer security problems are in fact economic problems. This is particularly relevant to LLM agents, because they have been shown to respond to incentives (Johnson and Obradovich 2022). Thus an important aspect of application security will be to ensure that our applications, which are now agents, have an incentive to behave well.
In the forthcoming series of posts, I’ll delve deeper into the security aspects of prompt-injection attacks and principal-agent problems from a MAS viewpoint, highlighting their economic and game-theoretical aspects.
I posit that the operating system will undergo a notable transformation. As apps evolve to mirror human behaviors and interactions, they will start to resemble employees working for a boss- the user. Consequently, the OS will metamorphose into a Human Resources (or perhaps better termed ‘Non-Human Resources’) department. This reimagined OS will act as a trusted intermediary, overseeing policies, permissions, and incentive structures for all agents within our devices—all of these communicated seamlessly through natural language.Subscribe
Bibliography
Greshake, Kai, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. “More Than You’ve Asked for: A Comprehensive Analysis of Novel Prompt Injection Threats to Application-Integrated Large Language Models.” arXiv Preprint arXiv:2302.12173.
Johnson, Tim, and Nick Obradovich. 2022. “Measuring an Artificial Intelligence Agent’s Trust in Humans Using Machine Incentives.” arXiv Preprint arXiv:2212.13371.
Labrou, Yannis, Tim Finin, and Yun Peng. 1999. “Agent Communication Languages: The Current Landscape.” IEEE Intelligent Systems and Their Applications 14 (2): 45–52.
Phelps, Steve, Peter McBurney, and Simon Parsons. 2010. “Evolutionary Mechanism Design: A Review.” Autonomous Agents and Multi-Agent Systems 21 (2): 237–64.
Phelps, Steve, and Rebecca Ranson. 2023. “Of Models and Tin Men–a Behavioural Economics Study of Principal-Agent Problems in AI Alignment Using Large-Language Models.” arXiv Preprint arXiv:2307.11137.
Wooldridge, Michael. 1997. “Agent-Based Computing.” Interoperable Communication Networks, no. 1 (September): 71–98.
No responses yet